

futureTEKnow
Editorial Team





















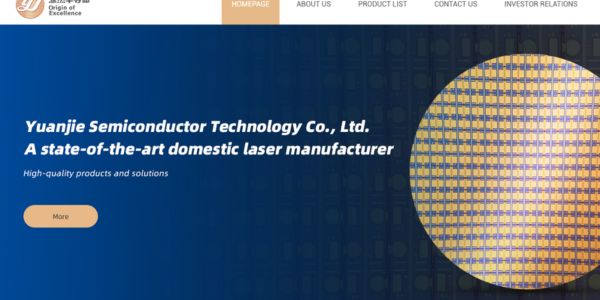
AI optics boom: how Yuanjie’s photonic chips became China’s quiet weapon in the data center arms race
Yuanjie Semiconductor’s photonic chips have gone from niche components to strategic assets in the AI data center race. This feature

Nvidia-backed Reflection AI eyes $2.5B round at $25B valuation to challenge DeepSeek and Western rivals
Nvidia-backed Reflection AI is seeking a $2.5B round at a $25B valuation to build open-weight coding models as a U.S.

Fusion rocket Sunbird ignites: Pulsar Fusion’s plasma breakthrough for faster deep-space travel
Pulsar Fusion’s Sunbird fusion rocket has achieved first plasma, validating its exhaust architecture and edging a reusable “space tug” concept

Aetherflux’s $2B orbital bet: space data centers for the AI age
Aetherflux is betting that orbital data centers can power the next wave of AI, shifting from laser power beaming to
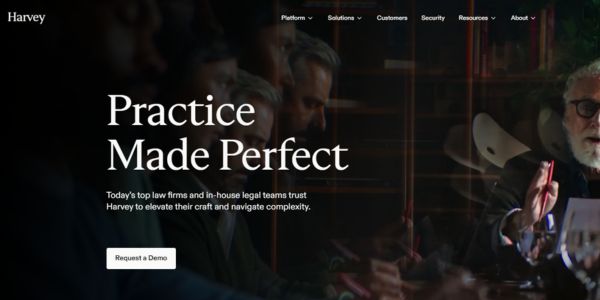
Harvey hits $11B valuation to become the platform where legal AI agents actually run work
Harvey has raised $200M at an $11B valuation to scale more than 25,000 custom AI agents across law firms and
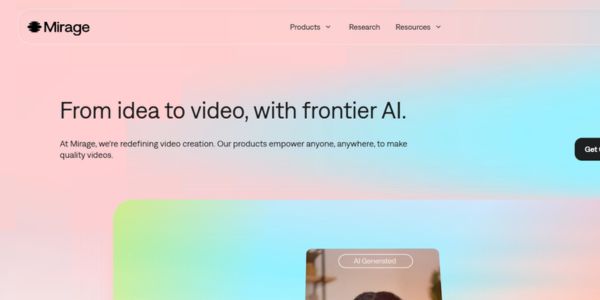
Mirage raises $75M to power new AI models behind its Captions video-editing app
Mirage, the company behind the Captions app, has raised $75M from General Catalyst’s Customer Value Fund to build new AI

Amazon’s Fauna Robotics acquisition signals next phase for humanoid robots
Amazon’s acquisition of Fauna Robotics brings the Sprout humanoid development platform into its Personal Robotics Group, highlighting a safety-first, developer-led

Interloom raises $16.5M to give AI agents “Enterprise Memory” for real‑world operations
Interloom has raised $16.5M to build an enterprise memory layer that captures expert decisions and gives AI agents the context
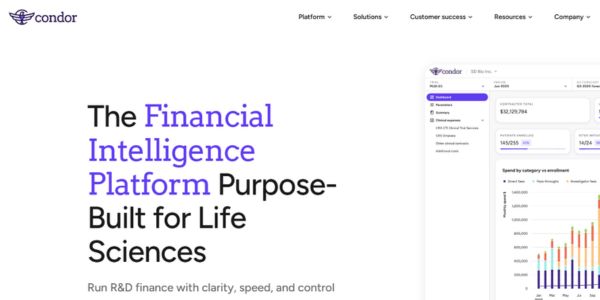
Condor Software lands $24M to give biopharma a clearer view of its R&D money
Condor Software has raised $24M to expand an AI-powered financial intelligence platform for life sciences, connecting clinical, operational and financial

WhiteBridge AI raises $3M to set a new standard for people search & research
WhiteBridge AI has raised a $3M seed round to advance its AI-powered people search and research engine. The platform turns

Mind Robotics’ $500M Series A backs AI-driven industrial automation shift
Mind Robotics has raised a $500 million Series A to build an AI-driven industrial automation platform trained on Rivian’s production
Legora raises $550M to build the AI operating system for legal work in the US
Legora has raised a $550M Series D at a $5.55B valuation to expand its collaborative AI platform for lawyers across